Encord Blog
Encord Monthly Wrap: February Industry Newsletter



Written by



Stephen Oladele
View more postsHi there,
Welcome the The Computer Vision Monthly Wrap
Here’s what you should expect:
📦 YOLOv9 release with an explainer and code walkthrough on creating custom datasets.
📸 Meta’s V-JEPA for prediction video features.
📽️ Understanding Sora, OpenAI’s text-to-video model.
⚒️ Developer resources to learn how to analyze object detection model errors.
☁️ Computer vision case study from NVIDIA and Oracle.
🚀 Lessons from working with computer vision operations (CVOps) at scale.
Let’s dive in!
Top Picks for Computer Vision Papers This Month
YOLOv9: Better than SoTA with Cutting-edge Real-time Object Detection
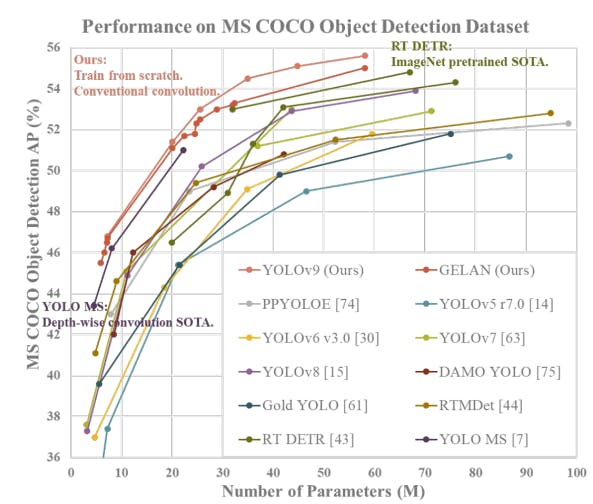
If you haven’t heard yet, YOLOv9 is out, and, wow, it’s a high-performant model! YOLOv9 builds upon previous versions, using advancements in deep learning techniques and architectural design to beat state-of-the-art (SoTA) object detection tasks.
What’s impressive? 🤯
- It achieves top performance in object detection tasks on benchmark datasets like MS COCO. It surpasses existing real-time object detectors (YOLOv6, YOLOv8) in terms of accuracy, speed, and overall performance.
- It is much more adaptable to different scenarios and use cases. We have started seeing various applications, including surveillance, autonomous vehicles, robotics, and more.
- It is better than SoTA methods that use depth-wise convolution because it uses both the Programmable Gradient Information (PGI) and GLEAN (Generative Latent Embeddings for Object Detection) architectures.
Read the paper on Arxiv. If that’s a lot, we also put out an explainer to help get to the important bits quickly with a walkthrough on using the open-source YOLOv9 release to create custom datasets.
There’s also an accompanying repository for the implementation of the paper.
Meta’s V-JEPA: Video Joint Embedding Predictive Architecture Explained
In February, Meta released V-JEPA, a vision model exclusively trained using a feature prediction objective. In contrast to conventional machine learning methods, which rely on pre-trained image encoders, text, or human annotations, V-JEPA learns directly from video data without external supervision.
What’s impressive? 👀
- Instead of reconstructing images or relying on pixel-level predictions, V-JEPA prioritizes video feature prediction. This approach leads to more efficient training and superior performance in downstream tasks.
- V-JEPA requires shorter training schedules than traditional pixel prediction methods (VideoMAE, Hiera, and OmniMAE) while maintaining high-performance levels.
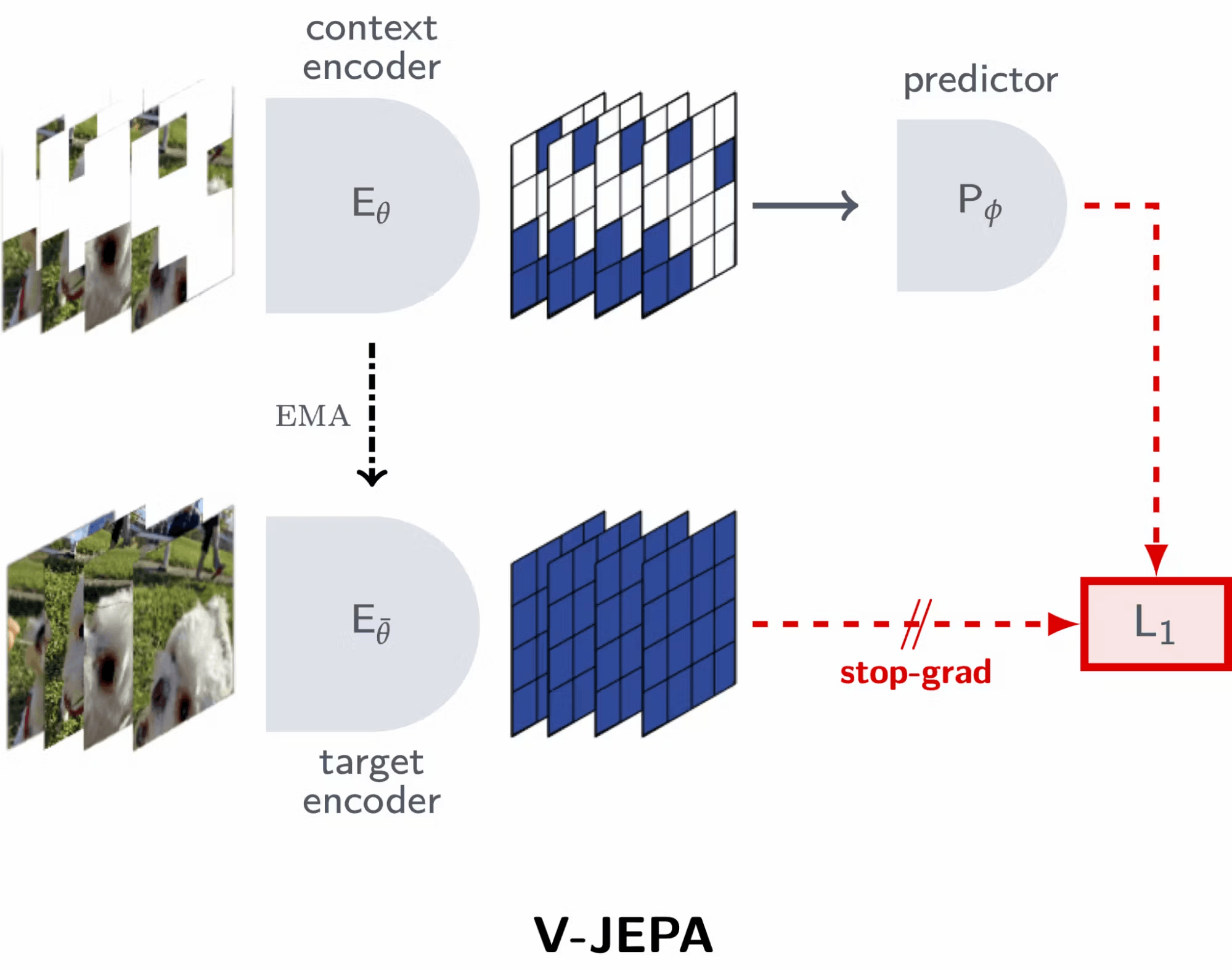
We wrote a comprehensive explainer of V-JEPA, including the architecture, key features, and performance details, in this blog post. Here is the accompanying repository on the implementation of V-JEPA.
OpenAI Releases New Text-to-Video Model, Sora
OpenAI responded to the recent debut of Google's Lumiere, a space-time diffusion model for video generation, by unveiling its own creation: Sora. The diffusion model can transform text descriptions into high-definition video clips for up to one minute. In this comprehensive explainer, you will learn:
- How Sora works
- Capabilities and limitations
- Safety considerations
- Other text-to-video generative models.
Gemini 1.5: Google's Generative AI Model with 1 Million-Token Context Length and MoE Architecture
Gemini 1.5 is a sparse mixture-of-experts (MoE) multimodal model with a context window of up to 1 million tokens in production and 10 million tokens in research. It excels at long-term recall and retrieval and generalizes zero-shot to long instructions, like analyzing 3 hours of video with near-perfect recall.
Here is an explainer blog that distils the technical report with the necessary information.
Developer Resources You’d Find Useful
- Multi-LoRA Composition for Image Generation → The space is moving so fast that it’s hard to miss out on gems like Multi-LoRA! The Multi-LoRA composition implementation integrates diverse elements like characters & clothing into a unified image to avoid the detail loss and distortion seen in traditional LoRA Merge. Check out the repo and try it yourself.
- Scaling MLOps for Computer Vision by MLOps.Community → In this panel conversation, experienced engineers talk about their experience, challenges, and best practices for working with computer vision operations (CVOps) at scale.
- How to Analyze Failure Modes of Object Detection Models for Debugging → This guide showcases how to use Encord Active to automatically identify and analyze the failure modes of a computer vision model to understand how well or poorly it performs in challenging real-world scenarios.
- NVIDIA Triton Server Serving at Oracle [Case Study] → I really liked this short case study by the Oracle Cloud team that discussed how their computer vision and data science services accelerate AI predictions using the NVIDIA Triton Inference Server. Some learnings in terms of cost savings and performance optimization are valuable.
Here are other quick finds if you 💓 Encord and computer vision data stuff ⚡:
- Join the Encord Community to discuss this newsletter.
- Data-centric computer vision blog.
Build better ML models with Encord
Get started todayWritten by
Stephen Oladele
View more postsRelated blogs



Meta’s V-JEPA: Video Joint Embedding Predictive Architecture Explained
Following the launch of I-JEPA last year, Meta has now rolled out V-JEPA as they accelerate efforts to envision Yann LeCun’s vision for Advanced Machine Intelligence. Yann LeCun, Vice President & Chief AI Scientist at Meta, asserts that "V-JEPA is a step toward a more grounded understanding of the world so machines can achieve more generalized reasoning and planning." This statement reiterates the broader goal of advancing machine intelligence to emulate human learning processes, where internal models of the world are constructed to facilitate learning, adaptation, and efficient planning in complex tasks. What is V-JEPA? V-JEPA is a vision model that is exclusively trained using a feature prediction objective. In contrast to conventional machine learning methods that rely on pre-trained image encoders, text, or human annotations, V-JEPA learns directly from video data without the need for external supervision. Key Features of V-JEPA Self-supervised Learning V-JEPA employs self-supervised learning techniques, enhancing its adaptability and versatility across various tasks without necessitating labeled data during the training phase. Feature Prediction Objective Instead of reconstructing images or relying on pixel-level predictions, V-JEPA prioritizes video feature prediction. This approach leads to more efficient training and superior performance in downstream tasks. Efficiency With V-JEPA, Meta has achieved significant efficiency gains, requiring shorter training schedules compared to traditional pixel prediction methods while maintaining high performance levels. Versatile Representations V-JEPA produces versatile visual representations that excel in both motion and appearance-based tasks, showcasing its effectiveness in capturing complex interactions within video data. V-JEPA Methodology Revisiting Feature Prediction for Learning Visual Representations from Video The AI model is trained using the VideoMix2M dataset, where it passively observes video pixels without explicit guidance. Through an unsupervised feature prediction objective, V-JEPA learns to predict features within the videos without relying on external labels or annotations, setting it apart from traditional approaches. The model does not utilize pretrained image encoders, text, negative examples, human annotations, or pixel-level reconstruction during its training process. Instead of directly decoding pixel-level information, V-JEPA makes predictions in latent space, distinguishing it from generative methods. A conditional diffusion model is then trained to decode these feature-space predictions into interpretable pixels, with the pre-trained V-JEPA encoder and predictor networks remaining frozen throughout this process. Importantly, the decoder is only provided with representations predicted for the missing regions of the video and does not access unmasked regions. This methodology ensures that the feature predictions made by V-JEPA exhibit spatio-temporal consistency with the unmasked regions of the video, contributing to its ability to produce versatile visual representations that perform well on downstream video and image tasks without the need for adapting the model's parameters. Advantages over Pixel Prediction V-JEPA makes predictions in an abstract representation space, allowing it to focus on higher-level conceptual information in videos without getting bogged down by irrelevant details. It's the first video model adept at "frozen evaluations," where pre-training on the encoder and predictor is done once and then left untouched. This means adapting the model for new tasks only requires training a lightweight specialized layer on top, making the process efficient and quick. Unlike previous methods that required full fine-tuning for each task, V-JEPA's approach enables reusing the same model parts for multiple tasks without the need for specialized training each time, demonstrating its versatility in tasks like action classification and object interactions. Revisiting Feature Prediction for Learning Visual Representations from Video V-JEPA Performance V-JEPA was trained on a vast dataset comprising 2 million videos sourced from public datasets. The model was then evaluated on a range of downstream image and video tasks, demonstrating impressive performance across the board. Comparison with Pixel Prediction V-JEPA was assessed against video approaches relying on pixel prediction, ensuring a consistent architecture across all baselines. Models such as VideoMAE, Hiera, and OmniMAE were evaluated using either a ViT-L/16 encoder or a Hiera-L encoder, which had similar parameters. The evaluation encompassed frozen evaluation with an attentive probe on downstream video and image tasks, as well as end-to-end fine-tuning. Revisiting Feature Prediction for Learning Visual Representations from Video V-JEPA exhibited superior performance across all downstream tasks in frozen evaluation, with the exception of ImageNet, where it achieved a comparable accuracy of 74.8% to the 75.1% attained by an OmniMAE model trained directly on ImageNet. Under the fine-tuning protocol, V-JEPA surpassed other models trained with a ViT-L/16, matching the performance of Hiera-L, while utilizing significantly fewer samples during pretraining, underscoring the efficiency of feature prediction as a learning principle. Comparison with State-of-the-Art models The performance of V-JEPA models, pre-trained on video, was compared against the largest state-of-the-art self-supervised image and video models. This comparison included various baselines, such as OpenCLIP, DINOv2, and I-JEPA for image-pretrained models, and VideoMAE, OmniMAE, Hiera, VideoMAEv2, and MVD for video-pretrained models. Revisiting Feature Prediction for Learning Visual Representations from Video The evaluation involved frozen evaluation with an attentive probe on downstream image and video tasks, showing V-JEPA's consistent improvement across all tasks, particularly excelling in tasks requiring motion understanding. It effectively reduced the gap between video and image models on tasks requiring static appearance-based features. V-JEPA Use-cases Video Understanding V-JEPA excels in understanding the content of various video streams, making it invaluable for computer vision tasks such as video classification, action recognition, and spatio-temporal action detection. Its ability to capture detailed object interactions and distinguish fine-grained actions sets it apart in the field of video understanding. Contextual AI Assistance The contextual understanding provided by V-JEPA lays the groundwork for developing AI assistants with a deeper understanding of their surroundings. Whether it's providing context-aware recommendations or assisting users in navigating complex environments, V-JEPA can enhance the capabilities of AI assistants in diverse scenarios. Augmented Reality (AR) Experiences V-JEPA's contextual understanding of video content can enrich AR experiences by providing relevant contextual information overlaid on the user's surroundings. Whether it's enhancing gaming experiences or providing real-time information overlays, V-JEPA can contribute to the development of immersive AR applications. With the release of Apple's Vision Pro, this technology could play a crucial role in enhancing mixed reality experiences. JEPA for Advanced Machine Intelligence (AMI) The primary focus of V-JEPA's development has centered on perception—grasping the contents of various video streams to gain an immediate contextual understanding of the world around us. The predictor within the Joint Embedding Predictive Architecture serves as an early physical world model, capable of conceptualizing what's happening within a video frame without needing to analyze every detail. Looking ahead, Meta's aim is to leverage this predictive model for planning and sequential decision-making tasks, expanding its utility beyond mere perception. Read the paper by Yann LeCun A Path Towards Autonomous Machine Intelligence for more information. As a research model, V-JEPA holds promise for various future applications. Its contextual understanding could prove invaluable for embodied AI endeavors and the development of contextual AI assistants for future augmented reality (AR) glasses. Emphasizing responsible open science, Meta has released the V-JEPA model under the CC BY-NC license, encouraging collaboration and further extension of this groundbreaking work in the AI research community. You can find V-JEPA’s open source code on Meta AI’s GitHub.
Feb 16 2024
8 M


Encord Monthly Wrap: January Industry Newsletter
Welcome to the January 2024 edition of Encord's Monthly Wrap. It’s also our chance to wish you a belated happy new year! Here’s what you should expect: Two interesting computer vision papers we reckon you check out. Hands-on tutorials you can work on during weekends. Developer resources you should bookmark, including Colab Notebooks. Computer vision use cases in manufacturing and robotics. Power tip for computer vision data explorers. Let’s dive in! Top Picks for Computer Vision Papers You Should See Segment Anything in Medical Images (MedSAM) This paper presents MedSAM, a novel adaptation of the Segment Anything Model (SAM) specifically for medical images. What’s impressive? 🤯 It introduces a large-scale medical image dataset with over 200,000 masks across 11 modalities and utilizes a fine-tuning method to adapt SAM for general medical image segmentation. It demonstrates superior performance over the original SAM, significantly improving the Dice Similarity Coefficient on 3D and 2D segmentation tasks. There’s also an accompanying repository with a shoutout to one of our pieces on fine-tuning SAM 😉. CLIP in Medical Imaging: A Comprehensive Survey This survey explores the Contrastive Language-Image Pre-Training (CLIP) application in the medical imaging domain. It delves into the adaptation of CLIP for image-text alignment and its implementation in various clinical tasks. What’s impressive? 👀 It provides an in-depth analysis of CLIP's utility in medical imaging, covering the challenges of adapting it to the specific requirements of medical images. It shows how well CLIP generalizes tasks like 2D and 3D medical image Fsegmentation, medical visual question answering (MedVQA), and generating medical reports. Illustration of CLIP’s generalizability via domain identification Medical professionals use Encord’s DICOM & NIfTI Editor to quickly label large training datasets across modalities such as CT, X-ray, ultrasound, mammography, and MRI. How Harvard Medical School and MGH Cut Down Annotation Time and Model Errors with Encord Stanford Medicine reduced experiment times by 80%. Floy reduced label times by 50% for CT and 20% for MRI scans. Want to get hands-on? Check Out These Computer Vision Tutorials [COLAB NOTEBOOK] How to Use the Depth Anything Model → The Depth Anything model is trained on 1.5 million labeled images and 62 million+ unlabeled images jointly and provides the most capable Monocular Depth Estimation (MDE) foundation models. This notebook shows you how to use the pipeline API to perform inference with any of the models. Here is the original paper (the image was adapted). How to Detect Data Quality Issues in Torchvision Dataset using Encord Active → This article shows you how to use Encord Active to explore images you have preloaded with Torchvision, identify and visualize potential issues, and take the next steps to rectify low-quality images. How to Use OpenCV With Tesseract for Real-Time Text Detection → This is a code walkthrough guide on building an app to perform real-time text detection from a webcam feed. Developer Resources You’d Find Useful How to Pre-Label Data at Speed with Bulk Classifications → If you're working with large unlabeled datasets and want to quickly classify and curate for labeling, you’ll find our tutorial on pre-labeling data at warping speed with bulk classification useful. Best Image Annotation Tools for Computer Vision [Updated 2024] → Choosing the right image annotation tool is a critical decision that can significantly impact the quality and efficiency of the annotation process. To make an informed choice, this article considers several factors and evaluates suitable image annotation tools for your business needs. Generate Synthetic Data for Deep Object Pose Estimation Training with NVIDIA Isaac ROS → NVIDIA developed Deep Object Pose Estimation (DOPE) to find the six degrees of freedom (DOF) poses of an object. In this article, they illustrated how to generate synthetic data to train a DOPE model for an object. Best Computer Vision Projects With Source Code And Dataset → An article with 16 ideas for computer vision projects for beginners and start building. Practical Computer Vision Use Cases Top 8 Use Cases of Computer Vision in Manufacturing → This article discusses the diverse applications of computer vision across various manufacturing industries, detailing their benefits and challenges, from product design and prototyping to operational safety and security. Top 8 Applications of Computer Vision in Robotics → This article explores computer vision applications in the robotics domain and mentions key challenges the industry faces today, from autonomous navigation and mapping to agricultural robotics. Top 3 Resources by Encord in January How to Adopt a Data-Centric AI → For data teams to succeed in the long term, they must use high-quality data to build successful AI applications. But what is the crucial sauce for building successful and sustainable AI based on high-quality data? A data-centric AI approach! We released this whitepaper to guide you on how to develop an effective data-centric AI strategy. Top 15 DICOM Viewers for Medical Imaging → In the market for a DICOM viewer? We published a comparison article that discusses what to look for in an ideal viewer and the options in the market so you can make the optimal choice. Instance Segmentation in Computer Vision: A Comprehensive Guide → We published an all-you-need-to-know guide on instance segmentation, including details on techniques like single-shot instance segmentation and transformer- and detection-based methods. We also cover the U-Net and Mask R-CNN architectures, practical applications of instance segmentation in medical imaging, and the challenges. Our Power Tip of the Month If you are trying to become a computer vision data power user, I’ve got a tip to help supercharge your exploration gauntlet (I see you, Thanos 😉). Within Encord Active, you can see the metric distribution of your data to identify potential data gaps that could influence model performance on outliers or edge cases. Here’s how to do it in 3 steps on the platform: Analytics >> Scroll down to Metric Distribution >> Choose a pre-built or custom Metric, and observe! Good stuff 🤩. I hope you find it useful. Here are other quick finds if you 💓 Encord and computer vision data stuff ⚡: Data-centric computer vision blog Join the Encord Community to discuss the resources GitHub repo The Docs Till next month, have a super-sparkly time!
Feb 01 2024
8 M


Gemini 1.5: Google's Generative AI Model with Mixture of Experts Architecture
In December 2023, Google launched the Gemini 1.0 family of models that outperformed state-of-the-art (SoTA) models in multimodal AI capabilities. Fast-forward to February 2024, and the Google Deepmind research team has launched Gemini 1.5 Pro with up to 10 million context windows! Not only that, it maintains near-perfect across the entire context and uses a mixture-of-experts (MoE) architecture for more efficient training & higher-quality responses. In this article, you will learn about: The superior performance benchmarks of Gemini 1.5 Why it performs better than SoTA at textual, visual, and audio capabilities How well it handles long-context tasks, especially with MoE as it’s architectural backbone How you can get started using it Before we jump into it, let’s set the tone with an overview of the MoE architecture that backs Gemini 1.5. TL;DR Gemini 1.5 is a Sparse mixture-of-experts (MoE) multimodal model with a context window of up to 10 million tokens. It excels at long-term recall and retrieval; generalizes zero-shot to long instructions like analyzing 3 hours of video, and 22 hours of audio with near-perfect recall. It performs better than Gemini 1.0 Pro and 1.0 Ultra but performs worse than 1.0 Ultra for audio and vision. Although there are no detailed insights on the model size, architectural experiments, or the number of experts, the model performs well at in-context memorization and generalization Mixture-of-Experts (MoE) Architecture Gemini 1.5 Pro uses a mixture-of-experts (MoE) architecture for efficient training & higher-quality responses, building on a long line of Google research efforts on sparse models. At its core, MoE diverges from traditional deep learning and Transformer architectures by introducing a dynamic routing mechanism that selectively activates different subsets of parameters (referred to as "experts") depending on the input data. It learns to selectively activate only the most relevant expert pathways in its neural network for nuanced and contextually aware outputs. This approach enables the model to scale more effectively in terms of computational efficiency and capacity without a linear increase in computational demands. In the context of Gemini 1.5, the MoE architecture contributes to efficient training and serving. Concentrating computational resources on the most relevant parts of the model for each input allows for faster convergence and improved performance without necessitating the proportional increase in computational power typically associated with scaling up the model size. Gemini 1.5 - Model Functionalities Gemini 1.5 drops with some impressive functionalities that beat SoTA models: Huge context window that spans up to 10 million-token context length Reduced training compute with the mixture-of-experts architecture Superior performance compared to Gemini 1.0 models, GPT-4, and other SoTA Huge Context Window A model’s “context window” comprises tokens, the building blocks for processing a user’s query. Tokens can be entire parts or subsections of words, images, videos, audio, or code. The bigger a model’s context window, the more information it can take in and process at a given prompt. Gemini 1.5 is a highly capable multimodal model with token context lengths ranging from 128K to 1 million token context lengths for production applications and up to 10 million for research. This unlocks a lot of use cases: Across reasoning about long text documents Making sense of an hour of video (full movies) 11 hours of audio Entire podcast series 700,000 words 30,000 lines of code simultaneously These capabilities are several times greater than other AI models, including OpenAI’s GPT-4, which powers ChatGPT. Context lengths of foundation models with Gemini 1.5 scaling up to 10 million tokens in research Reduced Training Compute The training compute required to train Gemini 1.5 were TPUv4 accelerators of multiple 4096-chip pods. This underscored the model's reliance on high-performance computing resources to perform well, but it also needed training efficiency techniques with the MoE architecture to be optimal. Gemini 1.5 significantly reduced compute requirements for training despite the larger context windows. This achievement is pivotal in the progress of AI model training efficiency, addressing one of the most pressing challenges in the field: the environmental and economic costs associated with training large-scale AI models. The reduction in training compute is primarily down to the Mixture-of-Experts (MoE) architectural backbone, which Gemini 1.5 uses to optimize computational resources. Beyond that, Gemini 1.5 incorporates state-of-the-art techniques such as sparsity in the model's parameters, which means that only a subset of the model's weights is updated during each training step. This approach reduces the computational load, leading to faster training times and lower energy consumption. According to the technical report, combining those processes to train the model led to remarkable performance without the proportional increase in resource consumption typically seen in less advanced models. Recalling and Reasoning Google Gemini 1.5 Pro sets a new standard in AI's ability to recall and reason across extensive multimodal contexts. The ten million-token context window—the largest of any foundational model, so far—enables Gemini 1.5 Pro to demonstrate unparalleled proficiency in synthesizing and interpreting vast amounts of information. Gemini 1.5 Pro achieves near-perfect recall in complex retrieval tasks across long text documents, videos, and audio, which shows its understanding of the input. In tests from the report, Gemini 1.5 Pro learned new languages from sparse instructional materials 🤯. This model's proficiency in recalling specific details from large datasets and its capability to apply this knowledge in reasoning tasks usher in a new era in AI applications—ranging from academic research and comprehensive code analysis to nuanced content creation. Superior Performance Benchmark Gemini 1.5 Pro demonstrates remarkable improvements over state-of-the-art (SotA) models, including GPT-4V, in tasks spanning text, code, vision, and audio. Some of the benchmarks for which Gemini 1.5 Pro achieves SotA accuracy include 1H-VideoQA and EgoSchema. This indicates Gemini 1.5 Pro's advanced long-context multimodal understanding. Learn more about how OpenAI’s GPT-Vision is expected to compare to the Gemini family of models in our explainer blog post. In core text evaluations, Gemini 1.5 Pro consistently outperforms its predecessors (Gemini 1.0 Pro and Ultra) in various domains such as Math, Science & Reasoning, Coding, Multilinguality, and Instruction Following. The model shows substantial improvements, particularly in Math and Science Reasoning, where it outperforms Gemini 1.0 Ultra, and in Coding tasks, it sets a new SotA accuracy benchmark on EgoSchema. Gemini 1.5 Pro's performance in multilingual evaluations highlights its enhanced ability to process and understand multiple languages. It shows significant improvements over both Gemini 1.0 models and other specialist models like USM and Whisper in speech understanding tasks. Needle In A Haystack (NIAH) Evaluation The Needle In A Haystack (NIAH) evaluation showcases Gemini 1.5 Pro's capability to retrieve specific information ("needle") from a massive amount of data ("haystack") across different modalities. This evaluation underscores the model's efficiency in long-context understanding and recall accuracy. Gemini 1.5 Pro achieves near-perfect “needle” recall (>99.7%) up to 1M tokens of “haystack” in all modalities (i.e., text, video audio) and maintains this recall performance when extending to 10 M tokens across modalities Context Window - Text Modality: Recall to Token Count Gemini 1.5 Pro excels in the text modality, with the model achieving over 99% recall for up to 10 million tokens, or approximately 7 million words. This capacity for deep, nuanced understanding and recall from vast quantities of text sets a new benchmark for AI performance in natural language processing. It can sift through large volumes of text to find specific information. Text needle-in-a-haystack task comparison between Gemini 1.5 Pro and GPT-4 Turbo The model demonstrates high recall rates for identifying exact text segments within extensive documents. Context Window - Audio Modality: Recall to Token Count Gemini 1.5 Pro demonstrates an exceptional ability to recall information from audio data, achieving near-perfect recall (>99.7%) up to 2 million tokens, equivalent to approximately 22 hours of audio content. It was able to recall and identify specific audio segments ("needles") embedded within long audio streams ("haystacks"). Audio version of the needle-in-a-haystack experiment comparing Gemini 1.5 Pro and a combination of Whisper and GPT-4 Turbo This represents a significant advancement over combining two SoTA models like Whisper + GPT-4 Turbo in a recall-to-token count comparison, which struggles with long-context audio processing. Context Window - Video Modality: Recall to Token Count Gemini 1.5 Pro maintains high recall performance in the video modality, successfully retrieving information from video data up to 2.8 million tokens, correlating to around 3 hours of video content. The "Video Needle In A Haystack" task tested the model's performance in recalling specific video frames from lengthy videos. This is critical for tasks requiring detailed understanding and analysis of long-duration video sequences. It can accurately pinpoint and recall specific moments or information from extensive video sequences. Multineedle in Haystack Test The researchers created a generalized version of the needle in a haystack test, where the model must retrieve 100 different needles hidden in the context window. The results? Gemini 1.5 Pro’s performance was above that of GPT-4 Turbo at small context lengths and remains relatively steady across the entire 1M context window. At the same time, the GPT-4 Turbo model drops off more quickly (and cannot go past 128k tokens). Multineedle in Haystack Test Textual Capabilities of Gemini 1.5 Mathematical and Scientific Textual Reasoning Gemini 1.5 Pro shows a +28.9% improvement over Gemini 1.0 Pro and a +5.2% improvement over Gemini 1.0 Ultra. This indicates a substantial increase in its ability to handle complex reasoning and problem-solving tasks. This proficiency is attributed to its extensive training dataset, which includes a wide array of scientific literature and mathematical problems, so the model can grasp and apply complex concepts accurately. Coding In Coding tasks, Gemini 1.5 Pro marked a +8.9% improvement over 1.0 Pro and +0.2% over 1.0 Ultra, showcasing its superior algorithmic understanding and code generation capabilities. The model can 𝐚𝐜𝐜𝐮𝐫𝐚𝐭𝐞𝐥𝐲 𝐚𝐧𝐚𝐥𝐲𝐳𝐞 an entire code library in a single prompt, without the need to fine-tune the model, including understanding and reasoning over small details that a developer might easily miss. Problem Solving Capability across 100,633 lines of code Instructional Understanding Gemini 1.5 Pro excels in Instruction Following, surpassing the 1.0 series in comprehending and executing complex (+9.2% over 1.0 Pro and +2.5% over 1.0 Ultra), multi-step instructions across various data formats and tasks. This indicates its advanced natural language understanding and ability to process and apply knowledge in a contextually relevant manner. Multilinguality The model also shows improvements in handling multiple languages, with a +22.3% improvement over 1.0 Pro and a slight +6.7% improvement over 1.0 Ultra. This highlights its capacity for language understanding and translation across diverse linguistic datasets. This makes it an invaluable tool for global communication and preserving and revitalizing endangered languages. Kalamang has almost no online presence. Machine Translation from One Book (MTOB: arxiv.org/abs/2309.16575) is a recently introduced benchmark evaluating the ability of a learning system to learn to translate Kalamang from just a single book. Gemini 1.5 Pro still translates the user prompt with astonishing accuracy. Visual Capabilities of Gemini 1.5 The model's multimodal understanding is outstanding in Image and Video Understanding tasks. Gemini 1.5 Pro's performance in these areas reflects its ability to interpret and analyze visual data, making it an indispensable tool for tasks requiring a nuanced understanding of text and media. Image and Video Understanding For image understanding, there's a +6.5% improvement over 1.0 Pro but a -4.1% difference compared to 1.0 Ultra. In video understanding, however, Gemini 1.5 Pro shows a significant +16.9% improvement over 1.0 Pro and +3.8% over 1.0 Ultra, indicating robust enhancements in processing and understanding visual content. These are some areas Gemini 1.5 performs great at: Contextual Understanding: Gemini 1.5 integrates visual data with textual descriptions, enabling it to understand the context and significance of visual elements in a comprehensive manner. This allows for nuanced interpretations that go beyond mere object recognition. Video Analysis: For video content, Gemini 1.5 demonstrates an advanced ability to track changes over time, recognize patterns, and predict outcomes. This includes understanding actions, events, and even the emotional tone of scenes and providing detailed analyses of video data. Image Processing: In image understanding, Gemini 1.5 utilizes state-of-the-art techniques to analyze and interpret images. This includes recognizing and categorizing objects, understanding spatial relationships, and extracting meaningful information from still visuals. Audio Capabilities of Gemini 1.5 Speech Recognition and Translation In an internal YouTube video-based benchmark, Gemini 1.5 Pro was evaluated on 15-minute segments, showing a remarkable ability to understand and transcribe speech with a word error rate (WER) significantly lower than that of its predecessors and other contemporary models. This capability is especially notable given the challenges posed by long audio segments, where the model maintains high accuracy without the need for segmentation or additional preprocessing. Gemini 1.5 Pro also performed well at translating spoken language from one language to another, maintaining the meaning and context of the original speech. This is particularly important for applications that require real-time or near-real-time translation. Overall, there are mixed results in the audio domain, with a +1.2% improvement in speech recognition over 1.0 Pro but a -5.0% change compared to 1.0 Ultra. In speech translation, Gemini 1.5 Pro shows a slight +0.3% improvement over 1.0 Pro but a -2.2% difference compared to 1.0 Ultra. Gemini 1.5 Core capabilities performance over its predecessor, Gemini 1.0 series of models, Gemini 1.0 Pro and Gemini 1.0 Ultra Long Context Understanding Gemini 1.5 Pro significantly expands the context length to multiple millions of tokens, enabling the model to process larger inputs effectively. This is a substantial improvement over models like Claude 2.1, which has a 200k token context window. Gemini 1.5 Pro maintains a 100% recall at 200k tokens and shows minimal reduction in recall up to 10 million tokens, highlighting its superior ability to manage and analyze extensive data sets. In one example, the model analyzed long, complex text documents, like Victor Hugo’s five-volume novel “Les Misérables” (1382 pages, 732k tokens). The researchers demonstrated multimodal capabilities by coarsely sketching a scene and saying, “Look at the event in this drawing. What page is this on?” With the entire text of Les Misérables in the prompt (1382 pages, 732k tokens), Gemini 1.5 Pro can identify and locate a famous scene from a hand-drawn sketch In another example, Gemini 1.5 Pro analyzed and summarized the 402-page transcripts from Apollo 11’s mission to the moon. “One small step for man, one giant leap for mankind.” Demo of Long Context Understanding Prompt In-Context Learning and the Machine Translation from One Book (MTOB) Benchmark Gemini 1.5 Pro can adapt and generate accurate responses based on minimal instruction. This capability is especially evident in complex tasks requiring understanding nuanced instructions or learning new concepts from a limited amount of information in the prompt. Gemini 1.5 Pro's in-context learning capabilities show its performance on the challenging Machine Translation from One Book (MTOB) benchmark. This benchmark tests the model's ability to learn to translate a new language from a single source of instructional material. In the MTOB benchmark, Gemini 1.5 Pro was tasked with translating between English and Kalamang, a language with a limited online presence and fewer than 200 speakers. Despite these challenges, the report showed that Gemini 1.5 Pro achieved translation quality comparable to that of human learners with the same instructional materials. This underscores the model's potential to support language learning and translation for underrepresented languages, opening new avenues for research and application in linguistics and beyond. Gemini 1.5 Pro Vs. Gemini Ultra While Gemini 1.5 Pro (2024) and Gemini Ultra (2023) are at the forefront of AI research and application, Gemini Pro 1.5 introduces several key advancements that differentiate it from Gemini Ultra. The table below provides an overview and comparison of both models. Use Cases Analyzing Lengthy Videos Analyzing videos is another great capability brought by the fact that Gemini models are naturally multimodal, and this becomes even more compelling with long contexts. In the technical report, Gemini 1.5 Pro was able to analyze movies, like Buster Keaton’s silent 45-minute “Sherlock Jr.” movie. Using one frame per second, the researchers turned the movie into an input context of 684k tokens. The model can then answer fairly complex questions about the video content, such as: “Tell me some key information from the piece of paper that is removed from the person’s pocket and the timecode of that moment.” Or, a very cursory line drawing of something that happened, combined with “What is the timecode when this happens?” Gemini 1.5 analyzing and reasoning over the 45-minute “Sherlock Jr.” movie You can see this interaction here: Multimodal prompting with a 44-minute movie Navigating Large and Unfamiliar Codebases As another code-related example, imagine you’re unfamiliar with a large codebase and want the model to help you understand the code or find where a particular functionality is implemented. In another example, the model can ingest an entire 116-file JAX code base (746k tokens) and help users identify the specific spot in the code that implements the backward pass for auto differentiation. It’s easy to see how the long context capabilities can be invaluable when diving into an unfamiliar code base or working with one you use daily. According to a technical lead, many Gemini team members have been finding it very useful to use Gemini 1.5 Pro’s long context capabilities on our Gemini code base. Gemini 1.5 navigating large and unfamiliar codebases What’s Next? According to a Google blog post, Gemini 1.5 Pro is currently in private preview, and its general availability with a standard 128,000-token context window will come later. Developers and enterprise customers can sign up to try Gemini 1.5 Pro with a context window of up to an experimental 1 million tokens via AI Studio and Google Vertex AI to upload hundreds of pages of text, entire code repos, and long videos and let Gemini reason across them. Try Gemini 1.5 Pro with a context window of up to an experimental 1 million tokens via AI Studio and Google Vertex AI That’s all for now. In the meantime, check out our resources on multimodal AI: Introduction to Multimodal Deep Learning GPT-4 Vision Alternatives Top Multimodal Annotation Tools
Feb 16 2024
10 M


Software To Help You Turn Your Data Into AI
Forget fragmented workflows, annotation tools, and Notebooks for building AI applications. Encord Data Engine accelerates every step of taking your model into production.