Contents
Top Picks for Computer Vision Papers This Month
Developer Resources You’d Find Useful
Encord Blog
Encord Monthly Wrap: March Industry Newsletter



Written by



Stephen Oladele
View more postsHi there,
Welcome to the Computer Vision Monthly Wrap for March 2024!
Here’s what you should expect:
- 🍏 MM1 - Methods, analysis, and insights from multimodal LLM pre-training by researchers at Apple.
- 📸 HyperLLaVA for developing adaptable and efficient AI systems that can excel across various multimodal tasks.
- 📽️ Understanding Mora, an open-source alternative to OpenAI’s text-to-video model.
- ⚒️ Developer resources to use for your next vision AI application.
- ☁️ Top 15 image segmentation repos for your next segmentation applications.
- 🤖 Google’s Video Gaming Companion: Scalable Instructable Multiworld Agent [SIMA].
Let’s dive in!
Top Picks for Computer Vision Papers This Month
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
This paper from Apple researchers is an in-depth analysis of multimodal large language model (MLLM) pre-training. They focused on developing efficient models by exploring architectural components and data selection strategies.
The study shows how integrating different kinds of data—such as text-only data, interleaved image-text, and image-caption pairs—can improve few-shot learning performance on a range of benchmarks. It is a big step forward for AI's ability to understand and process complex multimodal inputs.
What’s impressive? 🤯
- The researchers scaled the model using Mixture of Experts (MoE) and dense model variants, which shows its complex architecture and how it can improve performance by smartly distributing computing resources. This is crucial for ensuring the model can work well in many real-world applications.
- The model's superior few-shot learning performance across several benchmarks indicates impressive improvements in how AI learns from limited data and interleaved data, which could help us build agile and adaptable AI systems.
- The 30B (billion) parameter-dense model beats prior state-of-the-art (SOTA) on VQA (Visual Question Answering) dataset and captioning tasks.

How can you apply it? ⚒️
- If you are conducting multimodal AI research, consider applying insights from MM1's architectural decisions, training recipes, and data strategies to improve how you develop new AI models.
- You can use the model for creative tasks like generating and curating context-aware content across different media. This will make it easier for people to create interesting and useful content.
- If you are building recommendation engines, use them to analyze user preferences across different media types for more personalized content suggestions.
📜 Read the paper on Arxiv. If that’s a lot, we also put out an explainer that helps you quickly get to the important bits. It provides a walkthrough on how to use the open-source YOLOv9 release to create custom datasets.
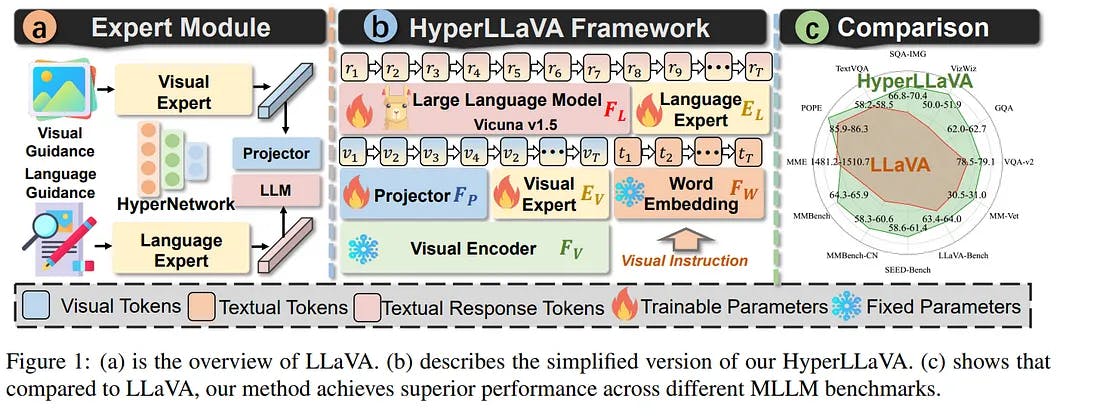
HyperLLaVA: Dynamic Visual and Language Expert Tuning for
Multimodal Large Language Models
Advancements in Multimodal Large Language Models (MLLMs) have shown that scaling them up improves their performance on downstream multimodal tasks. But the current static tuning strategy may constrain their performance across different tasks.
This paper discusses HyperLLaVA, a framework that circumvents the problems with static tuning methods by letting visual and language experts dynamically tune both the projector (which turns visual data into a format that language models can understand) and the LLM parameters.
What’s impressive? 👀
- It uses a unique training methodology that first aligns visual-language features and then refines language model tuning with multimodal instructions, optimizing the model’s comprehension and responsiveness.
- It shows amazing progress in MLLM benchmarks (MME, MMBench, SEED-Bench, and LLaVA-Bench), which opens the door for AI systems that are more nuanced, adaptable, and capable of handling complex multimodal data.
- Unlike static models, HyperLLaVA uses HyperNetworks to adaptively generate parameters for projectors and LLMs based on input, which helps with task-specific optimizations.
📜 Read the paper on Arxiv.
Google’s Video Gaming Companion: Scalable Instructable Multiworld Agent [SIMA]
How do you train an AI agent to be a generalist? Google DeepMind’s latest AI agent, SIMA, short for Scalable Instructable Multiworld Agent, helps us understand precisely how.
SIMA interacts with the environment in real-time using a generic human-like interface. It receives image observations and language instructions as inputs and generates keyboard and mouse actions as outputs. SIMA is trained on a dataset of video games, including Satisfactory, No Man's Sky, Goat Simulator 3, and Valheim.
Here is an explainer post that distills the technical paper with the most important bits you need to know.
MORA: The Advanced Multi-Agent Video Generation Framework
Mora is a multi-agent framework designed for generalist video generation. Based on OpenAI's Sora, it aims to replicate and expand the range of generalist video generation tasks. It distinguishes itself from Sora by integrating several visual AI agents into a cohesive system. Here are the video generation tasks it can do:
1️⃣ Text ➡️ Video
2️⃣ Text + Image ➡️ Video
3️⃣ Extending Videos 📈
4️⃣ Text + Video ➡️ Video
5️⃣ Video merging 🤝
6️⃣ Simulating digital worlds 🤖
Here is an explainer post that distills the technical paper with the most important bits you need to know.
Developer Resources You’d Find Useful
- Gemini 1.5 Pro API Support in AI Studio for Developers → Google started rolling out Gemini 1.5 Pro support for developers! This means you can start developing AI apps with Gemini 1.5 Pro, which comes with a standard 128,000 token context window, and you can build with the 1M token context window!
- 15 Interesting GitHub Repositories for Image Segmentation → If you are building an application involving image segmentation, this article includes 15 GitHub repositories that showcase different approaches to segmenting complex images.
- The Generative AI In-Vehicle Experience Powered by NVIDIA DRIVE → In a recent video, NVIDIA unveiled a new in-vehicle AI experience powered by NVIDIA DRIVE. This multimodal AI assistant can perceive, reason with, and assist drivers with features like surround visualization, access to a knowledge base, and the ability to read and understand text. This new experience will likely help with developing more context-aware autonomous vehicle systems.
Here are other quick finds if you 💓Encord and computer vision data stuff ⚡:
- Join the Encord Community to discuss this newsletter.
- Data-centric computer vision blog.
Till next month, have a super-sparkly time!
Build better ML models with Encord
Get started todayWritten by
Stephen Oladele
View more postsRelated blogs



Encord Monthly Wrap: February Industry Newsletter
Hi there, Welcome the The Computer Vision Monthly Wrap Here’s what you should expect: 📦 YOLOv9 release with an explainer and code walkthrough on creating custom datasets. 📸 Meta’s V-JEPA for prediction video features. 📽️ Understanding Sora, OpenAI’s text-to-video model. ⚒️ Developer resources to learn how to analyze object detection model errors. ☁️ Computer vision case study from NVIDIA and Oracle. 🚀 Lessons from working with computer vision operations (CVOps) at scale. Let’s dive in! Top Picks for Computer Vision Papers This Month YOLOv9: Better than SoTA with Cutting-edge Real-time Object Detection If you haven’t heard yet, YOLOv9 is out, and, wow, it’s a high-performant model! YOLOv9 builds upon previous versions, using advancements in deep learning techniques and architectural design to beat state-of-the-art (SoTA) object detection tasks. What’s impressive? 🤯 It achieves top performance in object detection tasks on benchmark datasets like MS COCO. It surpasses existing real-time object detectors (YOLOv6, YOLOv8) in terms of accuracy, speed, and overall performance. It is much more adaptable to different scenarios and use cases. We have started seeing various applications, including surveillance, autonomous vehicles, robotics, and more. It is better than SoTA methods that use depth-wise convolution because it uses both the Programmable Gradient Information (PGI) and GLEAN (Generative Latent Embeddings for Object Detection) architectures. Read the paper on Arxiv. If that’s a lot, we also put out an explainer to help get to the important bits quickly with a walkthrough on using the open-source YOLOv9 release to create custom datasets. There’s also an accompanying repository for the implementation of the paper. Meta’s V-JEPA: Video Joint Embedding Predictive Architecture Explained In February, Meta released V-JEPA, a vision model exclusively trained using a feature prediction objective. In contrast to conventional machine learning methods, which rely on pre-trained image encoders, text, or human annotations, V-JEPA learns directly from video data without external supervision. What’s impressive? 👀 Instead of reconstructing images or relying on pixel-level predictions, V-JEPA prioritizes video feature prediction. This approach leads to more efficient training and superior performance in downstream tasks. V-JEPA requires shorter training schedules than traditional pixel prediction methods (VideoMAE, Hiera, and OmniMAE) while maintaining high-performance levels. We wrote a comprehensive explainer of V-JEPA, including the architecture, key features, and performance details, in this blog post. Here is the accompanying repository on the implementation of V-JEPA. OpenAI Releases New Text-to-Video Model, Sora OpenAI responded to the recent debut of Google's Lumiere, a space-time diffusion model for video generation, by unveiling its own creation: Sora. The diffusion model can transform text descriptions into high-definition video clips for up to one minute. In this comprehensive explainer, you will learn: How Sora works Capabilities and limitations Safety considerations Other text-to-video generative models. Gemini 1.5: Google's Generative AI Model with 1 Million-Token Context Length and MoE Architecture Gemini 1.5 is a sparse mixture-of-experts (MoE) multimodal model with a context window of up to 1 million tokens in production and 10 million tokens in research. It excels at long-term recall and retrieval and generalizes zero-shot to long instructions, like analyzing 3 hours of video with near-perfect recall. Here is an explainer blog that distils the technical report with the necessary information. Developer Resources You’d Find Useful Multi-LoRA Composition for Image Generation → The space is moving so fast that it’s hard to miss out on gems like Multi-LoRA! The Multi-LoRA composition implementation integrates diverse elements like characters & clothing into a unified image to avoid the detail loss and distortion seen in traditional LoRA Merge. Check out the repo and try it yourself. Scaling MLOps for Computer Vision by MLOps.Community → In this panel conversation, experienced engineers talk about their experience, challenges, and best practices for working with computer vision operations (CVOps) at scale. How to Analyze Failure Modes of Object Detection Models for Debugging → This guide showcases how to use Encord Active to automatically identify and analyze the failure modes of a computer vision model to understand how well or poorly it performs in challenging real-world scenarios. NVIDIA Triton Server Serving at Oracle [Case Study] → I really liked this short case study by the Oracle Cloud team that discussed how their computer vision and data science services accelerate AI predictions using the NVIDIA Triton Inference Server. Some learnings in terms of cost savings and performance optimization are valuable. Here are other quick finds if you 💓 Encord and computer vision data stuff ⚡: Join the Encord Community to discuss this newsletter. Data-centric computer vision blog.
Mar 08 2024
10 M


Encord Monthly Wrap: January Industry Newsletter
Welcome to the January 2024 edition of Encord's Monthly Wrap. It’s also our chance to wish you a belated happy new year! Here’s what you should expect: Two interesting computer vision papers we reckon you check out. Hands-on tutorials you can work on during weekends. Developer resources you should bookmark, including Colab Notebooks. Computer vision use cases in manufacturing and robotics. Power tip for computer vision data explorers. Let’s dive in! Top Picks for Computer Vision Papers You Should See Segment Anything in Medical Images (MedSAM) This paper presents MedSAM, a novel adaptation of the Segment Anything Model (SAM) specifically for medical images. What’s impressive? 🤯 It introduces a large-scale medical image dataset with over 200,000 masks across 11 modalities and utilizes a fine-tuning method to adapt SAM for general medical image segmentation. It demonstrates superior performance over the original SAM, significantly improving the Dice Similarity Coefficient on 3D and 2D segmentation tasks. There’s also an accompanying repository with a shoutout to one of our pieces on fine-tuning SAM 😉. CLIP in Medical Imaging: A Comprehensive Survey This survey explores the Contrastive Language-Image Pre-Training (CLIP) application in the medical imaging domain. It delves into the adaptation of CLIP for image-text alignment and its implementation in various clinical tasks. What’s impressive? 👀 It provides an in-depth analysis of CLIP's utility in medical imaging, covering the challenges of adapting it to the specific requirements of medical images. It shows how well CLIP generalizes tasks like 2D and 3D medical image Fsegmentation, medical visual question answering (MedVQA), and generating medical reports. Illustration of CLIP’s generalizability via domain identification Medical professionals use Encord’s DICOM & NIfTI Editor to quickly label large training datasets across modalities such as CT, X-ray, ultrasound, mammography, and MRI. How Harvard Medical School and MGH Cut Down Annotation Time and Model Errors with Encord Stanford Medicine reduced experiment times by 80%. Floy reduced label times by 50% for CT and 20% for MRI scans. Want to get hands-on? Check Out These Computer Vision Tutorials [COLAB NOTEBOOK] How to Use the Depth Anything Model → The Depth Anything model is trained on 1.5 million labeled images and 62 million+ unlabeled images jointly and provides the most capable Monocular Depth Estimation (MDE) foundation models. This notebook shows you how to use the pipeline API to perform inference with any of the models. Here is the original paper (the image was adapted). How to Detect Data Quality Issues in Torchvision Dataset using Encord Active → This article shows you how to use Encord Active to explore images you have preloaded with Torchvision, identify and visualize potential issues, and take the next steps to rectify low-quality images. How to Use OpenCV With Tesseract for Real-Time Text Detection → This is a code walkthrough guide on building an app to perform real-time text detection from a webcam feed. Developer Resources You’d Find Useful How to Pre-Label Data at Speed with Bulk Classifications → If you're working with large unlabeled datasets and want to quickly classify and curate for labeling, you’ll find our tutorial on pre-labeling data at warping speed with bulk classification useful. Best Image Annotation Tools for Computer Vision [Updated 2024] → Choosing the right image annotation tool is a critical decision that can significantly impact the quality and efficiency of the annotation process. To make an informed choice, this article considers several factors and evaluates suitable image annotation tools for your business needs. Generate Synthetic Data for Deep Object Pose Estimation Training with NVIDIA Isaac ROS → NVIDIA developed Deep Object Pose Estimation (DOPE) to find the six degrees of freedom (DOF) poses of an object. In this article, they illustrated how to generate synthetic data to train a DOPE model for an object. Best Computer Vision Projects With Source Code And Dataset → An article with 16 ideas for computer vision projects for beginners and start building. Practical Computer Vision Use Cases Top 8 Use Cases of Computer Vision in Manufacturing → This article discusses the diverse applications of computer vision across various manufacturing industries, detailing their benefits and challenges, from product design and prototyping to operational safety and security. Top 8 Applications of Computer Vision in Robotics → This article explores computer vision applications in the robotics domain and mentions key challenges the industry faces today, from autonomous navigation and mapping to agricultural robotics. Top 3 Resources by Encord in January How to Adopt a Data-Centric AI → For data teams to succeed in the long term, they must use high-quality data to build successful AI applications. But what is the crucial sauce for building successful and sustainable AI based on high-quality data? A data-centric AI approach! We released this whitepaper to guide you on how to develop an effective data-centric AI strategy. Top 15 DICOM Viewers for Medical Imaging → In the market for a DICOM viewer? We published a comparison article that discusses what to look for in an ideal viewer and the options in the market so you can make the optimal choice. Instance Segmentation in Computer Vision: A Comprehensive Guide → We published an all-you-need-to-know guide on instance segmentation, including details on techniques like single-shot instance segmentation and transformer- and detection-based methods. We also cover the U-Net and Mask R-CNN architectures, practical applications of instance segmentation in medical imaging, and the challenges. Our Power Tip of the Month If you are trying to become a computer vision data power user, I’ve got a tip to help supercharge your exploration gauntlet (I see you, Thanos 😉). Within Encord Active, you can see the metric distribution of your data to identify potential data gaps that could influence model performance on outliers or edge cases. Here’s how to do it in 3 steps on the platform: Analytics >> Scroll down to Metric Distribution >> Choose a pre-built or custom Metric, and observe! Good stuff 🤩. I hope you find it useful. Here are other quick finds if you 💓 Encord and computer vision data stuff ⚡: Data-centric computer vision blog Join the Encord Community to discuss the resources GitHub repo The Docs Till next month, have a super-sparkly time!
Feb 02 2024
8 M


Software To Help You Turn Your Data Into AI
Forget fragmented workflows, annotation tools, and Notebooks for building AI applications. Encord Data Engine accelerates every step of taking your model into production.